GenAI Impact, the making of
- GenAI Impact
- Environmental impacts , Gen ai impact development
- April 30, 2024
Table of Contents
The global impact of using generative Artificial Intelligence remains a considerable gray area, despite—or perhaps because of—the incredible speed of its adoption by the general public. To address this, a hundred volunteers from the NGO Data For Good have come together under the banner “GenAI Impact”. Let’s find out how!
Info
This article was automatically translated from french to english.
What do we know today about the impact of digital technology? It accounts for 4% of global emissions (2.5% in France, due to its low-carbon energy), more than civil aviation, and is rapidly increasing: +60% by 2040 if nothing changes (source: ADEME/Arcep ).
But all these calculations predate the tech event that changed everything, at the end of 2022: the arrival of ChatGPT. OpenAI’s flagship application has shifted humanity into the era of generative AI (GenAI) following its adoption by hundreds of millions of users in record time. But what is the backlash?
Indeed, there is a significant backlash. For example, we know that GPU processors used for generative AI, or GenAI calculations, can consume between three and five times as much as CPU processors capable of performing some of the same tasks (source: Ampere Computing ). And that these same GPUs heat up 2.5 times more than comparable CPUs (source: manufacturer data). This suggests a significantly greater impact than pre-GenAI IT systems.
Another hidden issue: in public debates, only the impact of training GenAI models is discussed. To the extent that decision-makers, including a former Secretary of State for Digital Affairs, publicly declare that GenAI models generate the most emissions at the time of their training.
However, this is false. Where available studies only looked at the training of models, the Data for Good white paper “The Great Challenges of Generative AI ” shows that the inference of a GenAI model, i.e., its use, can generate more than 200 times more emissions per year than the training stage. Especially if it is a model as widely used as GPT 3.5, the model behind ChatGPT.
In this context, the “GenAI Impact ” project was born, an extension of the white paper’s work. Samuel Rincé , co-author and Lead AI Engineer at Alygne, leads the project with the support of several dozen volunteers from Data For Good. The goal? To explore the full implications of generative AI, including its rebound effects on society, such as the increase in software production and associated consumption: “Copilot is increasingly used, which boosts developer performance: we produce more code, and more software than before; but software has an impact. We make efficiency everywhere, so we produce more, we consume more, everywhere.”
How does the project manage to assess the impact of GenAI, concretely speaking, and then reduce it? This involves two main efforts.
First, the Modeling part aims to answer the question “how to assess the direct impacts of GenAI model inference?”
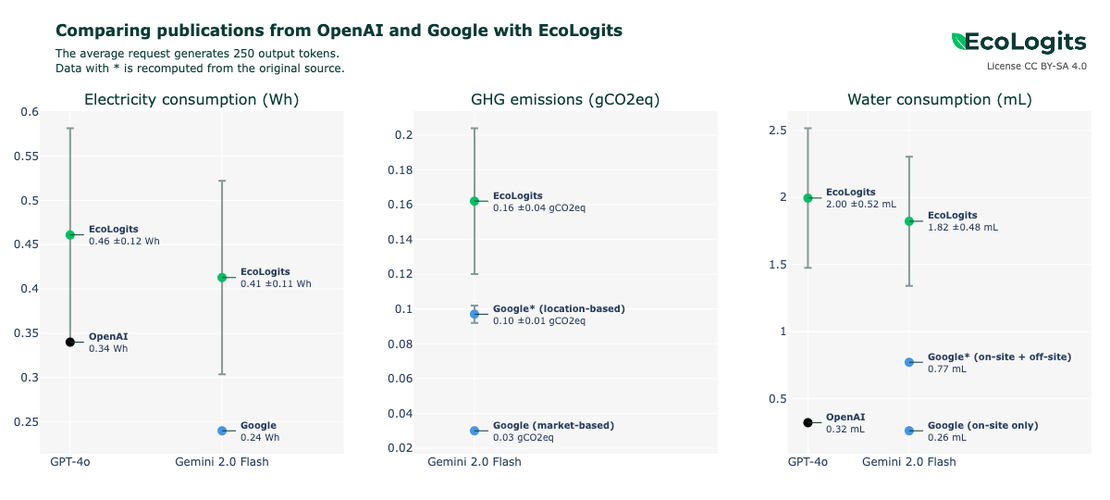
To do this, the project team will rely on open data available about a number of models, through tools like LLM-Perf Leaderboard (Hugging Face) and ML.energy . Then, a benchmark per request will estimate the energy consumption and impacts of the models. Thus, “if I make a request to a language model and it generates a text of a certain length, that is, a number of tokens, I can estimate how much energy the Large Language Model (LLM) has consumed,” explains Samuel Rincé. Data which are then verified by a peer review phase.
The Modeling part will go further than existing studies by looking at GenAI models “Sparse Mixture of Experts”, like Mixtral from Mistral AI, which generally go up to 70 billion parameters, as well as larger models, like Command R+ from Cohere (104 billion parameters).
For the former, the goal will be to assess the impacts of these models that use only part of their maximum computing capacity, which adds a significant variability factor. GPT-4 is suspected to be a sparse mixture of experts model of 1700 billion parameters that only activates a portion of these parameters by inference.
For the larger open models, the challenge will be to assess their impact across the multiple GPUs on which they are deployed, where smaller models use only one, specifies Samuel Rincé. This type of test “will confirm that our law also works for very large models.”
The GenAI Impact project will also go further than other studies by taking into account the energy consumption of the servers containing these famous GPUs, as well as their impacts on their life cycle, relying on the reference base created by the association Boavizta , to which Samuel Rincé also contributes.
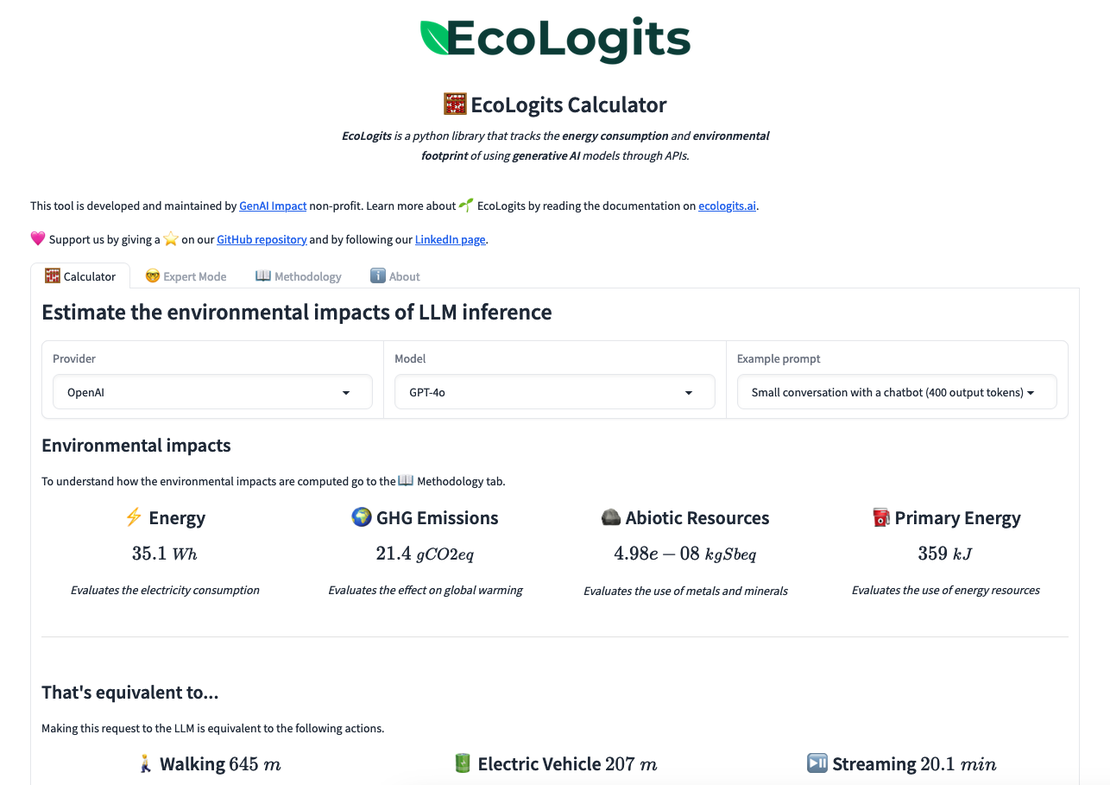
Finally, we must not limit ourselves to emissions: the impacts are multiple, and so are the measurement criteria. They also include, for example, primary energy, the consumption of resources like IT hardware components, and the water used by data centers containing AI supercomputers (a conversation with ChatGPT can consume half a liter of water for server cooling needs, for reference ).
All this work would obviously be for nothing if it stayed in its corner. Hence the other effort, Awareness, which aims to make the project’s methodological findings known. How? By going through the developer community.
If other levers have been considered by the working group - including a web browser plug-in that would display the emissions from using ChatGPT in real time, or storytelling around the topic “GenAI Impact” - these have been temporarily set aside in favor of a Python library named EcoLogits , a package to be made available to developers and organizations sensitive to the theme.
Why? “This allows us to first indirectly touch the organizations, and then multiply the impacts afterwards,” explains Samuel Rincé, sketching a hypothetical result: “if we think of the after-sales service chatbot, we could limit its emissions to a certain level, so that it hands over to a human after a certain number of wrong answers [in order not to emit too much for nothing].”
More concretely, in the current context, where few developers are incentivized to reduce the emissions generated by their work, the Python library would allow them to demonstrate this impact in the simplest and fastest way possible. And, these tools did not exist before.
Thanks to the work of the GenAI Impact group, a developer could, for example, combine EcoLogits data and CodeCarbon - another open-source library, which estimates the emissions generated by running the code - in their usual dashboards. Thus, the emissions of a model become a metric to follow like any other. Then, it would be possible to recommend one GenAI model over another because it emits less for equal performance. “We will have new trade-offs to make” thanks to the project, promises Samuel Rincé.
How will we know if the project has ‘worked’? The first goal would be the acceptance of the Python library by a large enough community of developers for it to be maintained in the long term as an open-source project by a ‘core’ team of a few developers. This long-term maintenance will attest to the quality of the work, and thus encourage more developers to use the library.
Subsequently, it will be necessary to ensure that the package integrates well into the current DevOps ecosystem; that other modalities can be added if necessary (e.g., image generation); and that all GenAI model creators (OpenAI, Anthropic, Mistral, and the like) are covered by the library.
In the future, specifies Caroline Jean-Pierre , Project Manager at Data for Good, there may be other projects, for example “raising public awareness through communication, improving impact assessment methodologies, or perhaps internationalizing the project?”
From there to influencing future legislation - even if that is not the primary goal of the project - there is only one step!
Author: James Martin
Revisions and corrections: Claire SAIGNOL , Andrea Leylavergne
Acknowledgments: Samuel Rincé , Caroline Jean-Pierre , Clément Collignon