GenAI Impact, le making of
Table des matières
L’impact planétaire de l’utilisation de l’Intelligence Artificielle générative reste une zone d’ombre considérable, malgré – ou peut-être à cause de – l’incroyable rapidité de son adoption par le grand public. Pour y remédier, une centaine de bénévoles de l’ONG Data For Good for se sont rassemblés sous la bannière “GenAI Impact”. Découvrons comment !
Que sait-on aujourd’hui de l’impact du numérique ? Il représente 4 % des émissions mondiales (2,5 % en France, en raison de son énergie peu carbonée), plus que l’aviation civile, et est en augmentation rapide : +60 % d’ici 2040 si rien ne change (source: ADEME/Arcep ).
Mais tous ces calculs datent d’avant l’événement tech qui aura tout changé, fin 2022 : l’arrivée de ChatGPT. L’application phare d’OpenAI a basculé l’humanité dans l’ère de l’IA générative (GenAI) suite à son adoption par des centaines de millions d’utilisateurs en un temps record. Mais quel est le retour de bâton ?
Alors que ce revers existe bel et bien. Nous savons, par exemple, que les processeurs GPU utilisés pour les calculs de l’IA générative, ou GenAI peuvent consommer entre trois et cinq fois que des processeurs CPU capables de faire certaines des mêmes tâches (source: Ampere Computing ). Et que ces mêmes GPUs chauffent 2.5 fois plus que des CPUs comparables (source: données fabricants). C’est donc un double effet kiss cool qui suggère un impact bien plus important que celui des systèmes IT pre-GenAI.
Autre arbre qui cache la forêt : dans les débats publics, on ne parle que de l’impact de l’entraînement des modèles de GenAI. À tel point que des décideurs, dont une ancienne Secrétaire d’Etat chargée du numérique, déclarent publiquement que les modèles de GenAI génèrent le plus d’émissions au moment de leur formation.
Or c’est faux. Là où les études disponibles ne regardaient que l’entraînement des modèles, le livre blanc de Data for Good “Les Grands défis de l’IA générative ” démontre que l’inférence d’un modèle GenAI, c’est-à-dire son utilisation, peut générer plus de 200 fois plus d’émissions par an que l’étape de son entraînement. Surtout s’il s’agit d’un modèle aussi largement utilisé que GPT 3.5, le modèle derrière ChatGPT.
Dans ce contexte, naît le projet “GenAI Impact ”, extension des travaux du livre blanc. Samuel Rincé , co-auteur et Lead AI Engineer chez Alygne, mène le projet avec le soutien de plusieurs dizaines de bénévoles de Data For Good. L’objectif ? Explorer les implications complètes de l’IA générative, y compris ses effets rebond sur la société, comme l’augmentation de la production de logiciels et de la consommation associée : “Copilot est de plus en plus utilisé, ce qui booste les performances du développeur : on produit plus de code, et plus de software qu’avant ; or le software a un impact. On fait de l’efficience partout, donc on produit plus, on consomme plus, partout.”
Comment le projet arrive-t-il à évaluer l’impact de la GenAI, concrètement parlant, et ensuite à les réduire ? Cela passe par deux chantiers.
D’abord, la partie Modélisation vise à répondre à la question “comment évaluer les impacts directs de l’inférence des modèles GenAI ?”
Pour ce faire, l’équipe du projet s’appuiera sur des données ouvertes disponibles à propos d’un certain nombre de modèles, via les outils LLM-Perf Leaderboard (Hugging Face) et ML.energy . Ensuite, un benchmark par requête permettra d’estimer la consommation énergétique et les impacts des modèles. Ainsi, “si je fais une demande à un modèle de langage et qu’il génère un texte d’une certaine longueur, c’est-à-dire un nombre de tokens, je peux estimer combien d’énergie le Large Langage Model (LLM) a consommé”,” explique Samuel Rincé. Données qui sont ensuite vérifiées par une phase de peer review.
La partie Modélisation ira plus loin que les études existantes en regardant des modèles GenAI “Sparse Mixture of Experts”, comme Mixtral de Mistral AI, qui vont en général jusqu’à 70 milliards de paramètres, ainsi que des modèles plus gros, comme Command R+ de Cohere (104 milliards de paramètres).
Pour les premiers, l’objectif sera d’évaluer les impacts de ces modèles qui n’utilisent qu’une partie de leur capacité de calcul maximale, ce qui ajoute un facteur de variabilité non-négligeable. On soupçonne GPT-4 d’être un modèle sparse mixture of experts de 1700 milliards de paramètres qui n’active qu’une portion de ces paramètres par inférence.
Pour les plus gros modèles ouverts, le défi consistera à évaluer leur impact à travers les multiples GPUs sur lesquels ils sont déployés, là où de plus petits modèles n’en utilisent qu’un seul, précise Samuel Rincé. Ce type de test “permettra de confirmer que notre loi fonctionne (aussi) pour de très gros modèles”.
Le projet GenAI Impact ira également plus loin que d’autres études en prenant en compte la consommation énergétique des serveurs contenant ces fameux GPUs, ainsi que leurs impacts sur leur cycle de vie, en s’appuyant sur la base de référence en la matière, créée par l’association Boavizta , à laquelle Samuel Rincé contribue également.
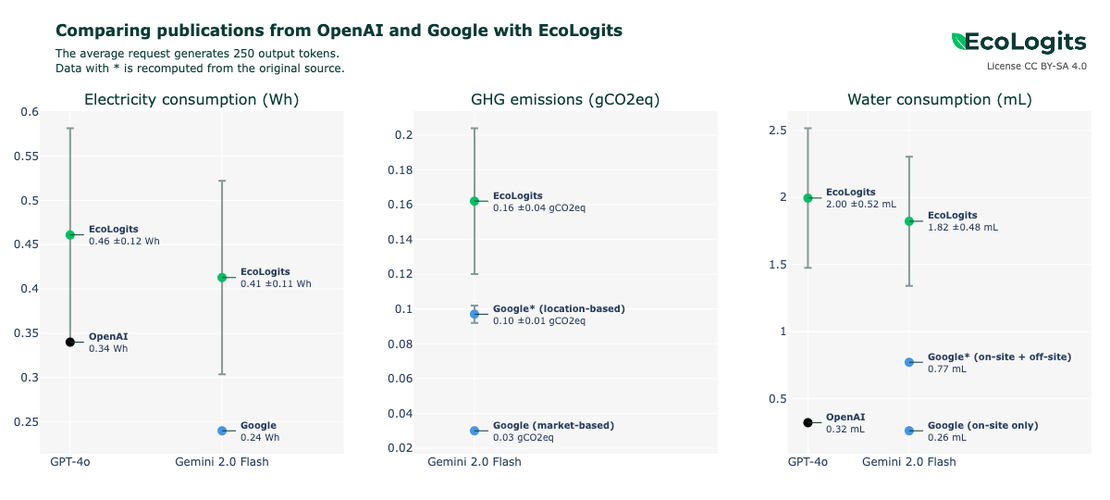
Enfin, il ne faut pas se limiter aux émissions : les impacts sont multiples, et donc les critères de mesure le sont aussi. Comptent également, par exemple, l’énergie primaire, la consommation de ressources comme les composants du hardware IT, et l’eau utilisée par les datacenters contenant les supercomputers IA (une conversation avec ChatGPT peut consommer un demi-litre d’eau en besoins de refroidissement des serveurs, pour rappel ).
Tout ce travail ne servira évidemment à rien s’il reste dans son coin. D’où l’autre chantier, de Sensibilisation, qui vise à faire savoir les trouvailles méthodologiques du projet. Comment ? En passant par la communauté des développeurs.
Si d’autres leviers ont été considérés par le groupe de travail - dont un plug-in pour navigateur web qui afficherait les émissions de l’utilisation de ChatGPT en temps réel, ou un storytelling autour du sujet “GenAI Impact” - ces derniers ont été temporairement mis de côté à la faveur d’une librairie Python dénommée EcoLogits , un package à mettre à disposition des développeurs et organisations sensibles à la thématique.
Pourquoi ? “Cela permet de toucher les organisations d’abord, indirectement, et de décupler les impacts par la suite,” explique Samuel Rincé, esquissant un résultat hypothétique : “si on pense au chatbot de service après-vente, on pourrait limiter ses émissions à un certain niveau, pour qu’il passe la main à un humain au bout d’un certain nombre de mauvaises réponses [afin de ne pas trop émettre pour rien].”
Plus concrètement, dans le contexte actuel, où peu de développeurs sont incentivés pour réduire les émissions générées par leur travail, la librairie Python leur permettrait de démontrer cet impact de la façon la plus simple et rapide possible. Or, ces outils n’existaient pas avant.
Grâce au travail du groupe GenAI Impact, un développeur pourrait, par exemple, combiner des données EcoLogits et CodeCarbon - autre librairie open source, qui estime les émissions générées par l’exécution du code - dans ses dashboards habituels. Ainsi, les émissions d’un modèle deviennent une métrique à suivre comme une autre. Ensuite, il serait possible de recommander un modèle GenAI plutôt qu’un autre parce qu’il émet moins à performance égale. “On aura de nouveaux arbitrages à faire” grâce au projet, promet Samuel Rincé.
Comment saura-t-on si le projet aura ‘fonctionné’ ? Le premier but serait l’acceptation de la librairie Python par une communauté de développeurs suffisamment importante pour qu’elle soit maintenue dans la durée comme projet open source par une équipe ‘core’ de quelques développeurs. C’est cette maintenance à long terme qui attestera de la qualité du travail, et donc qui incitera plus de développeurs à utiliser la librairie.
Par la suite, il faudra notamment s’assurer que le package s’intègre bien dans l’écosystème DevOps du moment ; que l’on puisse y ajouter d’autres modalités si besoin (ex. génération d’images) ; et que tous les créateurs de modèles GenAI (OpenAI, Anthropic, Mistral et compagnie) soient couverts par la librairie.
À l’avenir, précise Caroline Jean-Pierre , Cheffe de Projet chez Data for Good, il pourra y avoir d’autres chantiers, par exemple “sensibiliser le grand public via la communication, améliorer les méthodologies d’évaluation des impacts, ou pourquoi pas l’internationalisation du projet ?”
De là à influencer de futures législations - même si ce n’est pas le but premier du projet - il n’y a qu’un pas !
Auteur : James Martin
Révisions et corrections : Claire SAIGNOL , Andrea Leylavergne
Remerciements : Samuel Rincé , Caroline Jean-Pierre , Clément Collignon